
how it started
Our AI team i.e Bishow and Sangam reached out to me regarding an interesting concept. They had extracted detailed data from a complete Figma page based on a given design.
They asked me how feasible it would be to compare the rendered UI with the extracted Figma JSON data. I gave it some thought and told them I'd need a day or two to explore how Figma internally structures and renders its pages.
After that, I began digging into the extracted JSON...
minimal chunk of extracted json (original json was above 5k lines)
{
"id": "I1:127;334:12717",
"name": "Vector",
"type": "VECTOR",
"scrollBehavior": "SCROLLS",
"blendMode": "PASS_THROUGH",
"fills": [
{
"blendMode": "NORMAL",
"type": "SOLID",
"color": {
"r": 0.42352941632270813,
"g": 0.4588235318660736,
"b": 0.4901960790157318,
"a": 1
}
}
],
"strokes": [],
"strokeWeight": 1,
"strokeAlign": "INSIDE",
"styles": {
"fill": "1:18"
},
"absoluteBoundingBox": {
"x": 726.2999877929688,
"y": 573.64013671875,
"width": 12.399999618530273,
"height": 14
},
"absoluteRenderBounds": {
"x": 726.2999877929688,
"y": 573.64013671875,
"width": 12.4000244140625,
"height": 14
},
"constraints": {
"vertical": "SCALE",
"horizontal": "SCALE"
},
"effects": [],
"interactions": []
}extraction
extract essential properties from a Figma node
function extractText(node) {
if (!node.characters) return null;
return {
type: "text",
content: node.characters,
style: {
fontSize: node.style?.fontSize || 16,
fontWeight: node.style?.fontWeight || 400,
color: node.fills?.[0]?.color
? `rgba(${Math.round(node.fills[0].color.r * 255)}, ${Math.round(
node.fills[0].color.g * 255
)}, ${Math.round(node.fills[0].color.b * 255)}, ${
node.fills[0].color.a
})`
: "#000",
},
};
}
function extractContainer(node) {
return {
type: "container",
style: {
backgroundColor: node.fills?.[0]?.color
? `rgba(${Math.round(node.fills[0].color.r * 255)}, ${Math.round(
node.fills[0].color.g * 255
)}, ${Math.round(node.fills[0].color.b * 255)}, ${
node.fills[0].color.a
})`
: "transparent",
padding: node.paddingTop || 0,
},
children: node.children?.map(extractText).filter(Boolean) || [],
};
}Render those properties into HTML
function renderNode(node) {
if (node.type === "text") {
return `<p style="
font-size: ${node.style.fontSize}px;
font-weight: ${node.style.fontWeight};
color: ${node.style.color};
">${node.content}</p>`;
}
if (node.type === "container") {
return `<div style="
background-color: ${node.style.backgroundColor};
padding: ${node.style.padding}px;
">
${node.children.map(renderNode).join("")}
</div>`;
}
return "";
}result
After re-running the code multiple times and fine-tuning it through trial and error, I was able to achieve the highest visual accuracy — closely matching the Figma design, which I was fully satisfied with.
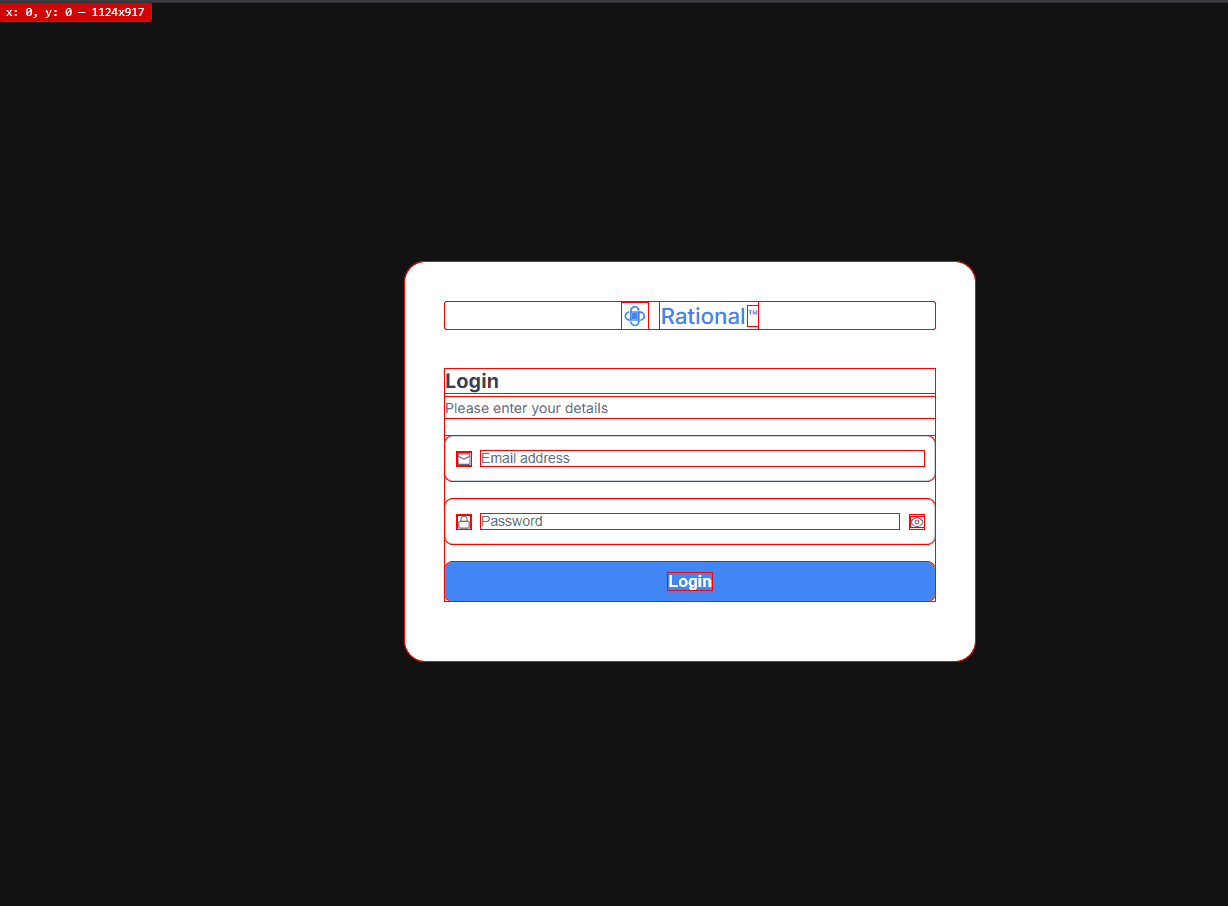

findings
-
An important observation from the above JSON snippet is that we can compare UI elements based on their x and y coordinates provided in the absoluteBoundingBox. However, to ensure accurate alignment and avoid floating-point mismatches, it's essential to properly round these coordinates — using something like Math.round() — before comparing them to the rendered UI.
-
Also from this, we can deduce that colors in the Figma JSON are always represented in RGBA format, where each component ranges from (0 to 1). However, this format isn't directly usable in standard UI rendering, which expects color values in the 0–255 range. Therefore, we need to multiply each RGB component by 255 to get the correct visual output.
-
One visual limitation we hit is with images. Although the JSON describes them (type: IMAGE), Figma doesn’t embed actual image URLs. To render images accurately, we must hit the Figma API’s /images endpoint and resolve imageRef to a real asset URL. Until then, only the image’s name appears — which is like seeing a placeholder, not the real thing.